
概念及入门
前言
在数据领域,有几类经典的查询场景:
- 想要统计某段时间内访问某网站的 UV 数,或是统计某段时间内既访问了页面 A 又访问了页面 B 的 UV 数,亦或是统计某段时间内访问了页面 A 但未访问页面 B 的 UV 数,通常我们对这种查询叫做基数统计。
- 想要观察某些指标的数据分布,例如统计某段时间范围内访问页面 A 与页面 B 各自的浏览时长 95 分位数、50 分位数,则需要用到分位数统计。
- 想要统计某段时间内播放量最多或者点击率最高的 10 个视频或者文章(热榜列表),则需要用到 TopN 统计。
这几类问题在数据量不大的情况下都是非常容易处理的。我们可以通过遍历+排序轻易而准确的解决这种问题。但一旦数据到达 Billion 量级,常规算法可能要花费数小时甚至数天的时间,并且即使提供充足的计算资源也于事无补,因为这几类问题都难以并行化处理。
DataSketches[1] 就是为了解决大数据和实时场景下的这几类典型问题而诞生的一组算法,最初由雅虎开源。这些算法以牺牲查询结果的精确性为代价,可以在极小的空间内并行、快速地解决上述几类问题。
Sketch 结构的核心思想
Sketch 结构即「数据草图」结构,主要是为了计算海量的流式数据的概率指标而设计的一种数据结构。一般占用固定大小的内存,不随着数据量的增加而增大。这种结构通过巧妙地保存或丢弃一些数据的策略,将数据流的信息抽象存储起来,汇总成 Sketch 结构,最终能根据 Sketch 结构还原始数据的分布,实现基数统计、分位数计算等操作。
Sketch、Summary 都可以理解为数据草图,不同论文中使用的称呼不太一致,但是符号一般都是大写的 S。
Sketch 一般具有以下几个特征:
1. 单次遍历
可以把 Sketch 理解为一个状态存储器,它时刻承载着数据流迄今为止的所有历史信息,因此 Sketch 通常是 single-pass 的,只需要遍历一遍数据即可取得所需的统计信息。
2. 占用空间小
传统的统计方式需要维护一个巨大的数据列表,且随着数据的输入越来越大。Sketch 可以在很小的常量空间内摄入海量的数据,通常在 KB 量级。这使得 Sketch 在海量数据的统计中非常有优势。
对于一个包含上亿条数据、包含多个维度组合的数据集,可以在每个维度组合上转化生成一个 KB 大小的 Sketch 结构,从而加快查询。


3. 可合并性
可合并性使得 Sketch 可以自由地分布式并行处理大量数据,因此具有快速、高效的优势。以基数统计 (Distinct Value, DV)为例,要解决的问题是从具有重复元素的数据流中查找不同元素的数量,Sketch 可以轻易地将局部统计结果合并为全局统计结果,而直接计数则做不到这一点,即:
DV(uid | city=北京 or 上海) ≠ DV(uid | city=北京) + DV(uid | city=上海)
Sketch(uid | city=北京 or 上海) = Sketch(uid | city=北京) + Sketch(uid | city=上海)
PS: 第二个式子中的加号代表 Sketch 的合并操作。
在分布式计算中,两个处在不同机器的 Sketch 的局部统计结果可以直接通过一个 QUERY 方法合并成一个 Sketch 结构,进行最终的分位数查询。

4. 误差可控的近似值
Sketch 为了节省空间必然会丢失一部分信息,因此统计结果不可能是完全精确的。但在现实中,许多分析和决策也并不要求数据是绝对精确的,有时候知道某个统计数据在 1% 的误差范围内往往跟精确的答案一样有效。Sketch 可以在计算复杂度与误差之间进行权衡,足以满足大数据场景下大部分的统计需求。
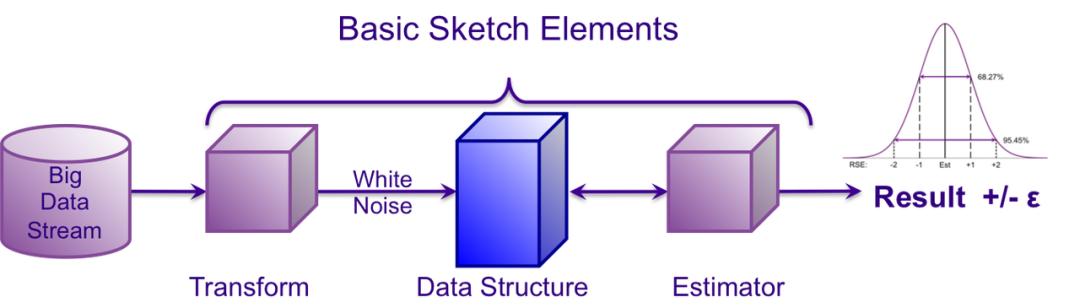
一个 Sketch 算法的使用流程通常如下:
原始数据经过转化生成一个 Sketch 结构,当要进行查询的时候,从 Sketch 生成一个 Estimator 返回查询结果
Quantile 的定义
分位点/分位数(Quantile):考虑误差近似,即给定误差 ε 和分位点 φ,只需要给定排序区间[(φ – ε)*N, (φ + ε)*N] 内的任意元素即可(N 为元素个数)。
举个例子,如果给定 input 序列如下,在 ε= 0.1 的情况下,求 PCT50(即 φ = 0.5)。返回 24、39、51 都是可以满足条件的。但如果 ε= 0.01,只有返回 39 才是正确的结果。
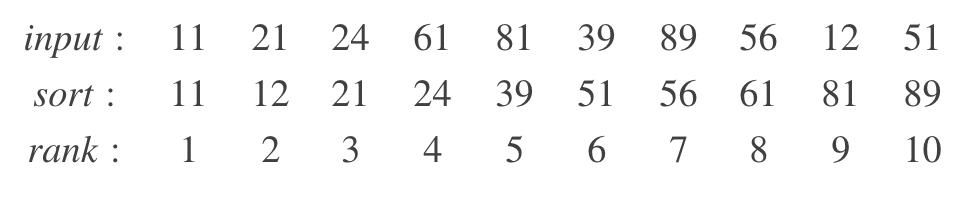
φ= 0.5 and ε = 0.1
Rank = [4, 5, 6] → V = [24, 39, 51]
这也就是为什么我们使用 DoublesSketch UDF 或者 Spark 的分位数近似算法的时候可能会出现分位数计算结果不准确的问题。此外,不同的分位数定位方法也会导致数据有细微的差距,后面会提及。
图中,在当前维度下的数据只有两条,针对这两条数据求 50 分位数的结果会不一样。在小基数求分位数问题的时候,数据会出现较大的误差。
Quantile 的误差
quantile 和 rank 实际上是两个函数:
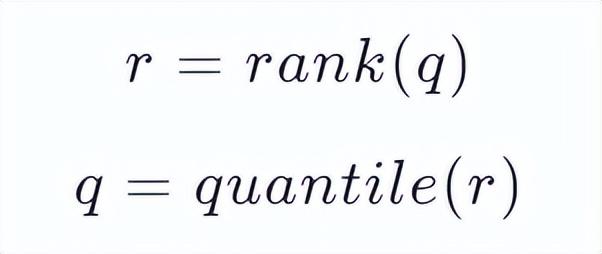
我们期待一对完美的函数,使得 q = quantile(rank(q)) 或者 r = rank(quantile(r)),但现实中,我们往往只能得到两个有误差的函数 r' = rank(q)和 q' = quantile(r)
分位数问题其实就是 quantile(r)问题,即给定 r,根据估计出来的 quantile 函数求出 q'。
函数的误差由多种途径带来:
- 海量数据必然导致我们需要对数据进行有条件的整合和过滤,由此引入误差。但合理的整合、过滤机制能够将误差控制在一定范围内。为此,无数 researcher 贡献了各种 idea,这也是文档后半部分介绍的主要内容。
- 重复值也会带来误差。但实际上,如果我们对分位点的定义和边界条件做了正确的假设,那么这种误差已经被考虑在了算法之内,本文不再做详细解释。举一个简单的例子给大家感受一下,不同分位数定位方法与重复值是如何带来误差的:
Example
有五个数据输入进来计算分位点:{10, 20, 20, 20, 30}
上边是原始数据经过排序后的数值和位置对应图,下边则可以想象成一个简单的存储了这些数据的 Sketch 结构。


在计算分位点的时候有两种定位分位点的规则,LT (less-than) 和 LE (less-than or equals)。两者在举例中有区别,但是上升到泛化问题上则区别不大,都属于可接受误差范围内,在这个例子中我们对比 LT 和 LE 规则下得到的结果,能发现在重复值 20 上的 Rank' 和 Quantile' 是不一样的,并且在边界上的值的 Rank' 和 Quantile' 也有误差。
LT (less-than) & GT(greater-than)

LE (less-than or equals) & GE(greater-than-or-equal)

想了解 LT 和 LE 规则的区别可以浏览 DataSketches 官网里关于 Quantiles 的定义[2]
业界 Quantile 实现
Quantile Sketches 经过层层迭代和不断的演进,已经形成多种变种。以 Apache DataSketches 中的实现总结[3]为例,很多 Sketches 算法早已应用在了诸如 Spark、Hive、Druid 等等大数据开发常用框架中,当我们在 SQL 中调用 percentile 类函数的时候,不同框架会调用其对应的算法。但由于不同框架实现的算法不一样,实现的效率也有高低,最终会导致在使用的时候能明显感知到计算速度的差异。
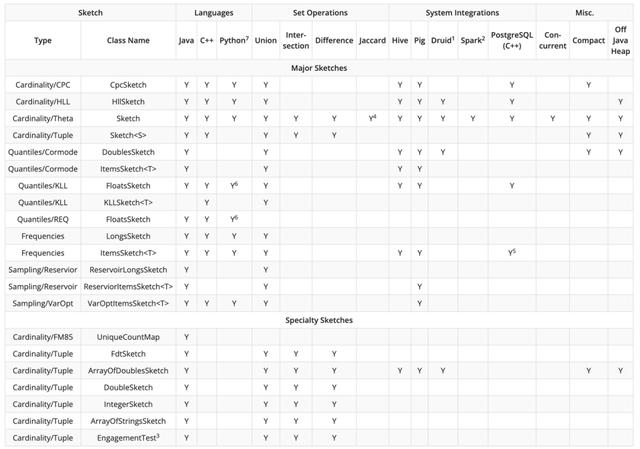
KLL 和 GK 算法应该是目前被应用最广泛的算法。这里,我们选取两个大数据开发场景下最常用的两个框架 Spark 和 Hive 来举例,对比其中的分位数计算函数 percentile_approx 与一个由 Apache DataSketches 提供的算法实现,并简单讲解一下如何将 Apache DataSketches 提供的更高效的算法引入日常开发工作中。
Spark
在 Spark 中计算分位数不需要引入 UDF,Spark 中的 ApproximatePercentile[4] 类实现了 GK 算法,以 QuantileSummaries[5] 的结构作为数据 Sketch,后面会提到 GK 算法并且简单解释其概念。这个函数在数据量小的时候的计算效率是比较快的。

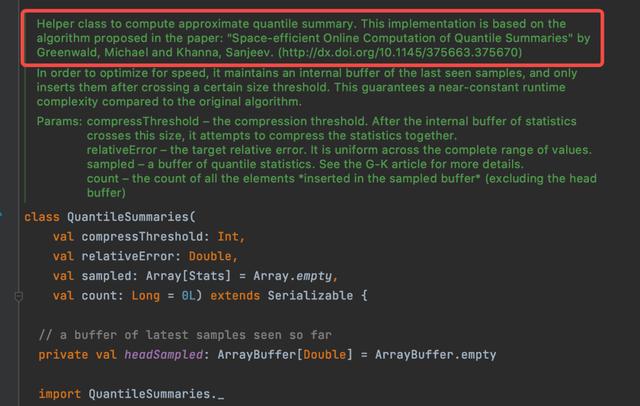
Hive
同样,在 Hive 中计算分位数可以直接使用原生的分位数计算方法,但该方法背后算法并没有 Spark 中的算法效率高效。Hive 中的 GenericUDAFPercentileApprox[6] 是通过计算近似数据直方图的方式估算分位数。如 Hive 源码提示,这个函数在数据量巨大的时候可能存在 OOM 的问题。此外,Hive 实现估计直方图的算法主要依据 A Streaming Parallel Decision Tree Algorithm[7]。值得一提的是,这个算法的核心想法是如何在有限的内存中构建数据的直方图。

DataSketches
如果在面对海量数据的时候,Spark 原生分位数计算函数会显得乏力,这时候就推荐引入 DataSketches 提供的分位数计算方法。该算法不光在空间占用上更优,其计算效率也更高。DataSketches 的 DoubleSketch[8] 是根据 Mergeable Summaries[9] 中提到的 Low Discrepancy Mergeable Quantiles Sketch 算法实现的。这篇论文主要讨论了什么是 Mergeability 并对之前著名的算法的 Mergeability 进行了证明。同时提出了一个结合抽样的 Randomized Mergeable Quantiles Sketch 算法。

作为大数据开发同学,对于该算法需要了解以下几点:
- 这个算法的 Sketch 结构能够分布式进行。
- 由于算法引入随机,每次的结果可能不同(但可以通过指定随机种子来固定)。
- 算法实现上通过压缩、位图等操作进一步节省时空开销。
- 能用这个算法就用这个算法,快得很!
算法落地到日常开发也很容易,Datasketches 已经提供了多种 UDF、UDAF,基本能够满足常见业务需求。需要先在 pom 文件中加入 org.apache.datasketches 依赖,然后可以根据业务需求,对 datasketches 提供的 UDF、UDAF 再次封装。打包成 jar 包并注册 UDF 之后,就可以在 SQL 中使用了。
Quantile Sketches 算法的演进过程
问题定义
Quantile Sketches 算法最早可以追溯到上世纪 90 年代,当流式数据以及分布式计算的概念刚刚在学术界得到普遍的认可,这个问题被抛了出来。如何在海量数据中,甚至无限数据中,使用有限的空间,找到其中的某一个 rank 对应的值,或找到某一个数对应的 rank。
Quantile Sketches 算法的发展依据重要的算法的推出,形成了几个重要的阶段。实际上,这个领域的初心是如何使用最小的内存空间,解决一个最泛化的问题。

什么是最泛化的问题呢?学术界把这种问题称为 All Quantiles Approximation Problem,其定义如下:

与最泛化问题相对应,狭义问题被称为 Single Quantile Approximation Problem。当然还有很多问题的变体,例如,给定 rank 求对应的数值(最常见的分位数问题)或者已知流数据大小求解 rank 或分位数等。
在明确了问题定义后,同样也需要明确对算法的定义,一个合格的 Quantile Estimators 应该具备以下四种特性:
- 提供可调节的、可以被明确的误差区间。
- 与输入数据独立。
- 只遍历一次所有数据。
- 应使用尽可能小的内存。
合格的 Estimator 并没有对可合并性作出什么显性的要求,mergeability 只是一个 nice to have 的特性。问题定义中并没有考虑 mergeability 的问题,所以有些算法没有实现 mergeability,导致无法完全适配实际生产中的分布式计算模式。即使适配,往往也需要更多空间,更高的计算复杂度。
空间优化的终点在哪里?
业界和学术对于探索未知的东西往往具有相同的方法论:先找到最小内存占用的天花板在哪里。通过构造特殊的对抗数据流并且证明了在极端情况下,任何算法都需要的最小的内存。如何找到这个问题的天花板并不是本文的重点,感兴趣的读者可以阅读论文 An Ω (1/ε log 1/ε) Space Lower Bound for Finding ε-Approximate Quantiles in a Data Stream[10] 进一步了解。
从压缩出发 – MRL 算法[11]
最简单的压缩
数据丢弃
回想之前讲解基础概念的时候提及的例子,我们可以直观的感受到,Sketch 数据结构的一个特性就是对数据进行合理的压缩。压缩后的数据尽可能的能够全面还原数据原本的分布。为了实现这一原理,最直观的想法就是针对每一个输入数据通过某种规则选择丢弃或保留,并确保将误差控制在 ε 以内。那么问题就变成了如何找到合适的丢弃规则。
举个例子,可以根据数据的 index 来判断是否丢弃:对于一个未排序的数据流,丢弃所有偶数位的数字,而保留奇数位的数字。但这显然是一个有缺陷的方法,而且很容易证明:只需要构建一个数据流,将所有较小的数据都放在偶数位,那么留下的数据则都是较大的数据,其中最小的数据也会大于或等于中位数。
从这个例子中得到启发,我们可以先对数据流进行排序,然后再根据上面的原则来丢弃数据,那么这个方法就变得可行了。
权重增加
另一个显而易见的逻辑是,丢弃的数据不能单纯地丢弃,它的信息必须以某种方式保存在未丢弃的数据中。继续上例,偶数位置的数据被丢弃,可以同时增大它前一个奇数位置数据的权重,使得一个奇数位数字表示原本一个奇数位+偶数位的数字。这样,数据量的信息就保存了下来,权重越大,也就意味着在这个区域内的数据越多。
Batch 思想
然而流数据并不支持实时排序,并且随着数据规模增大,排序所需要的时间和空间开销都会不断增长。一个自然的想法是,可以把流数据划分成一个个的 batch,在每一个 batch 内部排序。
下图中的例子结合了数据丢弃和权重增加两个策略。其中,第一行是输入数据被切分成一个个小 batch 并经过内部排序后的样子。第二行表示丢弃所有偶数位的数据,并增加前一位奇数位数据的权重(小方格的高度增大了一倍)。第三行表示丢弃所有奇数位的数据,并增加后一位偶数位数据的权重。可以观察到,一些位置的 Rank 发生改变,如果 Compactor 内部数据是偶数的时候 Rank 不发生改变,如果是奇数则会相对加一或减一。按照这个过程就可以构建一个最简单的 Sketch 结构。

单个 batch 数据压缩问题的思路得到了初步的验证,那么问题来了,单个 batch 如何推演到多个 batch 甚至流数据上的呢?
压缩与合并
假设有两个 Sketch 结构,我们想要达成的效果是,当把这两个 Sketch 结构合并成一个之后,仍然能够提供准确的 Rank。
如下图所示,红点表示数据 s_i < v,当我们把两个 Sketch 结构合并后发现,v 在合并后的数据集中的 Rank 就等于两个 Sketch 分别统计红点个数的和,合并数据集的 Rank 不会因为拆分统计而变化。
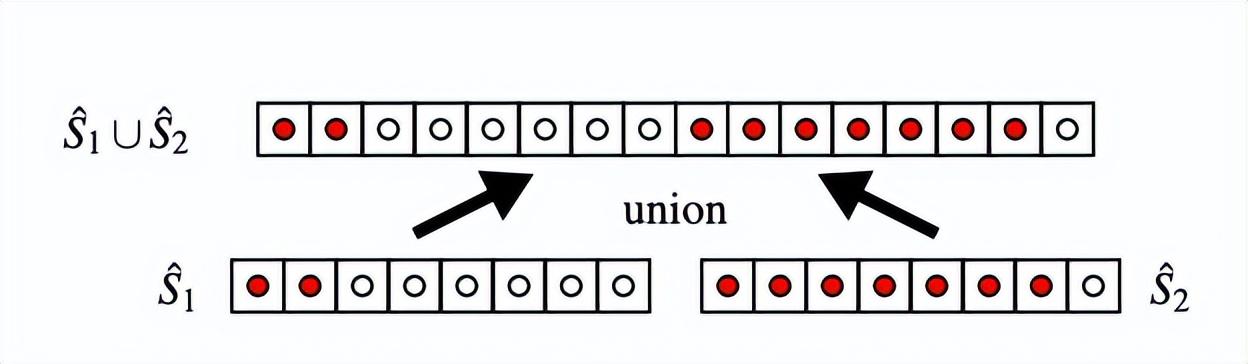
因此,我们得到两条推论:

但如果单纯地把两组数据拼接在一起,显然会面临数据量增加带来的空间开销增大的问题。此时再回到之前提到的压缩、合并的思路,可以将这个过程不断循环起来,即合并、压缩、再合并、再压缩……
MRL 算法原理简介
Random Sampling Techniques for Space Efficient Online Computation of Order Statistics of Large Datasets[11](MRL 算法)就是在压缩、合并思想上加以改进得来的。MRL 算法构建了一个树状多层级压缩合并结构:
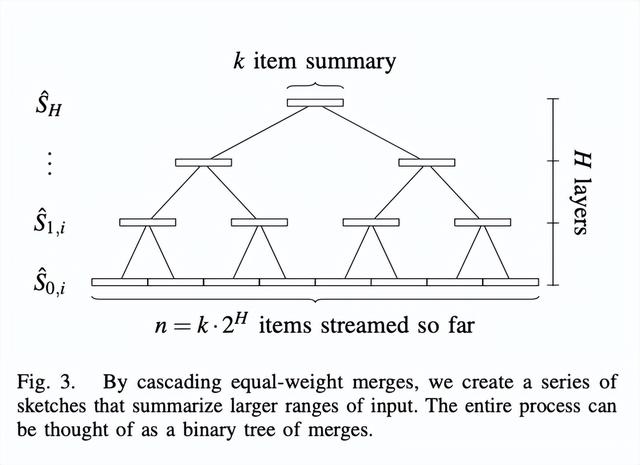
选择一个固定大小的 k 作为 Sketch 结构的大小。根据流数据量大小可以反推需要压缩的层级数 H。显然,k 越大压缩层级越少,相对丢失的信息就越少,结果就越精确。
过程很简单,原始流数据输出到 level0 的一个 Sketch 结构中,当数据填满了大小为 k 的 Sketch 结构后,如果 level0 没有其他 Sketch,则这个 Sketch 暂时缓存下来,等待另一个 Sketch 到来。如果有另一个 Sketch,则将两个 Sketch 归并排序后保留所有奇数位置的数据,将 2k 大小的数据压缩为 k 大小并传入下一层级。同样,如果下一层级已经存在一个 Sketch,那么进行类似的归并排序和丢弃压缩后,将 Sketch 传入下一层级,层层递进。
k 的大小直接影响数据准确性,甚至还决定了这个算法能否收敛,比较合适的取值为 k = O(ε^{?1} _ log^2(εn))。MRL 算法在每一层级只需要两个 Sketch 结构存储数据。层级数决定了所需要的总共空间大小,而层级数的是根据总数据量和单个 Sketch 结构大小推演得到的:
O(H) = O(log^2(n/k)) = O(log^2(εn)), 总共空间 O(kH) = O(ε^{-1} _ log^2(εn))。
从抽样出发 – Sample 算法[12]
假如现有一亿个数字,我们想要对其中的某一个数字 x 求他的 Rank 是多少,Reservoir-Based Random Sampling with Replacement from Data Stream[12] 告诉我们,通过随机抽样我们可以用下面的公式从样本估计整体的 Rank:
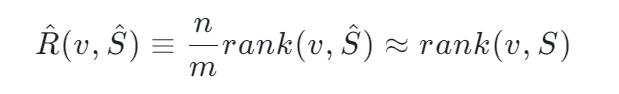
但这个是一个近似公式。一个严谨的算法需要搞清楚,这东西有多近似。碰巧存在这么一个不等式 Hoeffding's inequality 并根据 Hoeffding's inequality 推出了这么一个定理
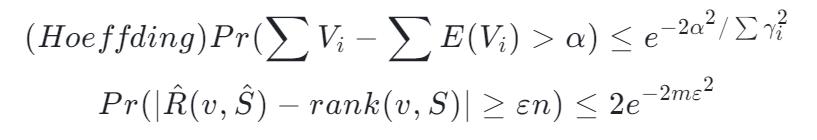
作为使用方,能理解证明是最好的,所以指路这篇文章的 VI 部分[13]。但是如果不理解证明,那么下面这段话会告诉你这个证明干了什么,有什么重要的意义(个人理解,可能存在不准确的地方,欢迎指正)。
本质上,Hoeffding's inequality 给出了随机变量的和与其期望值偏差的概率上限。这个不等式是一个 Bernoulli 过程的一个衍生(关于 Hoeffding's inequality 更详细的指路这里[14])。这种随机抽样到估计一个数字的 Rank 也是存在联系的(误差上限)。这种上限恰巧能够让把估计误差限定在一个范围内,满足了 Quantile Sketch 算法的要求。况且抽样的过程将 Rank 结果与数据量 n 独立开来。结果的误差只取决于 m。而 m 是我们可以设定的一个数,换句话说,m 是我们可以设定的一个内存大小,这个内存大小决定了抽样后估计的 Rank 的误差上限。
可以观察到,这里所需要的内存大于 MRL 算法。但是它的最大意义在于移除了与数据量大小 n 的关系。需要明确的是,这种抽样需要预先知道数据量大小 n,如果不知道数据量大小 n,抽样仍然是有用的,但需要随着数据量增大而降低抽样概率。详情见[13]
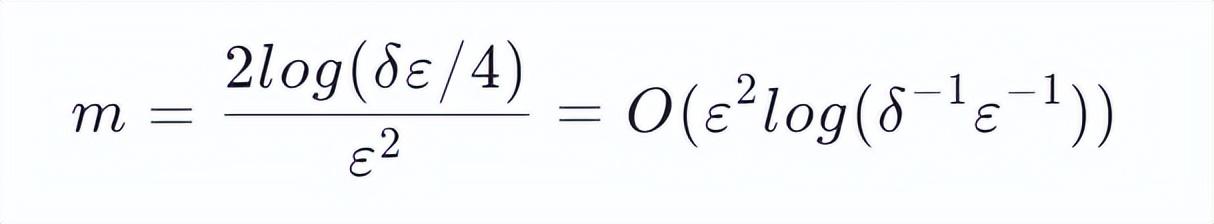
从结构出发 – GK 算法[15]
Summary 结构设计
GK 算法 Space-Efficient Online Computation of Quantile Summaries[15] 的灵感来源于下面这个想法:假设我们收到的流数据的第一个数字就是中位数,那么我们只需要随着数据的输入统计大于这个数的数量和小于这个数的数量,最后就能很轻易的验证这个数是不是中位数。我们能不能对 k 个输入的数据都保持这个一个结构,记录大于这个结构的数据的个数和小于这个结构的数据的个数,那能找到对应数字的 Rank 是多少了。
存在下面一个结构,每一个 tuple 存储真实值、最小 Rank、最大 Rank,每一个 tuple 叫 Summary:
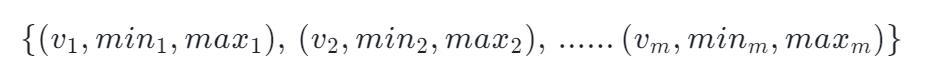
对于任意数据,只要满足下面的公式,那么算法总体误差就是收敛的。
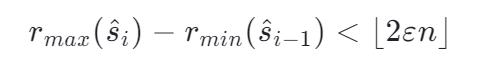
但是这个结构存在缺陷。在处理流数据的时候,如果新来的数据需要插入中间,那么每次都需要更新后面所有的 Summary。这样更新的复杂度实在太高了。GK 算法就此提出了一个针对插入数据操作更友好的 Summary 结构:
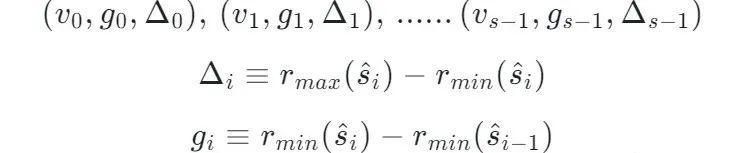
将绝对位置转化成相对位置进行表示。
- g 表示两个相邻 Summary 的相对位置差异,根据 g 和一个起始点我们能够推演出这个起始点和 Summary 的距离是多少。
- Δ 表示这个 Summary 覆盖的 Rank 的范围是多少。

根据这个上面这个定义能推论出一下三条性质,详细的推论这里不再赘述,有兴趣的可以看这篇文章[16][17]

结合 Summary 结构的一些操作
经过一番数据公式的狂轰滥炸后,好像又摸不着 GK 算法在干什么了。如果想了解 GK 算法的细节,指路原始论文[15]。但如果仅仅想了解算法的思想,那么上面这都不重要,下面这段话告诉你这么一圈折腾到底为了什么。
如同数据库的增删改查一样,构建这么一个特殊的 Summary 结构并推到这么多性质,只是为了更快、更方便的实行以下这些操作:
- 构建一个 Summary + 一个特殊的 INSERT() 方法 -> 使得更新数据特别快。
- 构建一个 Summary + 一个特殊的 QUERY() 方法 -> 使得查询满足误差约束。
- 构建一个 Summary + 一个特殊的 DELETE() 方法 + 一个特殊的 COMPRESS() 方法 -> 使得空间保持不变且最优。
INSERT

最大最小情况都很好理解。对于一般情况,新插入的数据 i 显然对 i-1 前面的任何数据都没有影响,但是后面的数据每一个 Rank 都应该增加一位 ,所以 g = 1。精妙之处就在于用相对位置的变化累加而表示了绝对位置的变化。Δ = g_i + Δ_i – 1 的原因后文会提及。
QUERY
All Quantiles Approximation Problem 有一条必须要满足的性质就是所有 x 都应该满足|R'(x) ? R(x)| ≤ εn,白话文解释就是,当我们发起一个查询的时候(查询 x 对应的 Rank)返回值的误差都应该保持在一个与数据量成正比的线性关系中。
巧妙的设置查询的方式就能将总体误差控制在收敛范围内。
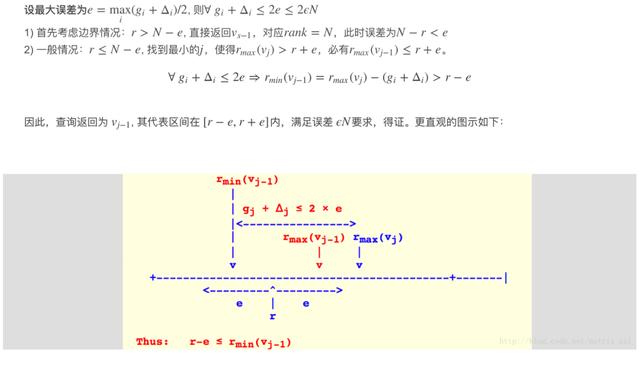


DELETE and COMPRESS
面对海量的数据,单纯的增加信息而不对信息做压缩删减显然是不合理的。删除规则如下:

删除操作只改变 v_i+1 所在 Summary 的 g_i+1, 并不改变 Δ_i+1。也就是说 Δ 越小,在满足误差约束下,具有合并更多 Summary 的潜力。
为了更加高效的对数据进行压缩 GK 算法又提出了 Fullness、Capacity 和 Bands 三个概念。


这三个概念的诞生就是为了辅助进行 COMPRESS 操作的,简单讲,每个 Summary 对应的 Capacity 大小,从右向左来看,大小称指数级倍数增大 ,而压缩也是从右向左进行的。下图展示了不同大小 Sketch 对应的每一个小的 Summary 的 Capacity 大小的关系,

下面的伪代码展示了一个压缩过程。满足压缩条件时,对 Summary 结构从右向左进行合并,使得 Summary 先尝试最少的内存方法。

满足压缩条件后,相邻 Summary 经过 COMPRESS 操作后,数据更新到 Band 值较小的 Summary 上。由于 DELETE 操作并不改变 Δ 的特性,如果保留 Band 值大的 Summary 结构,便有了更大的 Capacity,后期也就能够容纳更多的 Summary(将更多的 Summary 压缩到一起)。
此外,GK 算法还引入了树模型,通过右先序遍历二叉树,实现对于子节点的快速有序 COMPRESS 到父节点操作,不过,这里不再详细介绍,感兴趣的同学可以指路原始论文[15]。
需要注意的是,GK 算法是一个 mergeable 的算法,准确来说,是一个 One-way mergeable 的算法。
One-way mergeability is a weaker form of mergeability that informally states that the following setting can work: The data is partitioned among several machine, each creates a Summary of its own data, and a single process merges all of the summaries into a single one. 换句话说,One-way mergeability merge 算法不能够分布式进行,否则误差不在可控范围内,而 Fully mergeable 的算法可以,虽然论文中对这点描述的不是特别清楚,但是详细证明指路这几篇讲解 [18][19][20]。
GK 到底好在哪?
说了这么多 GK 算法的原理,这算法到底好在哪里?
- GK 算法以一种独特的方式存储了数据信息,实现了海量数据的高效查询,高效插入。
- GK 算法在原本的树状模型上引入了不同层级则不同大小的 Summary 结构,更高效的利用了空间。
融合之开端 – ACHPWY 算法[9]
中国古话常讲,取其精华,去其糟粕。后面的算法切实贯彻了这种思想。ACHPWY 算法 Mergeable Summaries[9] 的 Low Discrepancy Mergeable Quantiles Sketch 是一个基于 MRL 算法的衍生算法。在 MRL 算法上又增加随机抽样的方式,使得最终得到的 Quantile Estimator 是一个无偏的 Estimator。ACHPWY 算法的整体架构和 MRL 算法一样,都采用相同的大小为 k 的 Sketch 结构,组成多层级树状模型。唯一不同的是,在进行 Sketch 合并的时候,引入随机变量 F 来决定取奇数位置数据还是偶数位置数据。


原本 MRL 算法在任何合并时只取奇数位,随机的引入带来了 unbiased Estimator,并且带来更少的空间使用空间的。如同上文解释的一样,如果需要探讨随机变量的和与其期望值偏差的概率上限,那么 Hoeffding's inequality 一定不会缺席的。具体的证明和讲解请参考[9][13]。
而对空间使用大小的估计和 MRL 算法原理一样,都是需要选择一个合适的 k 作为 Sketch 结构的大小以达到空间最优的目的。总共需要的内存大小在 MRL 算法基础上更进一步。

此外,相较于其他算法,ACHPWY 算法更加清楚的定义并证明了 One-way mergeability 在其算法的可行性。并且证明了 Same-weight merges 情况和 Uneven-weight merges 情况下的的可行性(误差收敛),使得分布式的 merge 操作实现有了基础。
融合之大锅炖 – KLL 算法[21]
KLL 算法原理简介
KLL 算法 Optimal Quantile Approximation in Streams[21] 可以理解为融合了之前提及的所有算法的优点,在空间上做出了极致的压缩,并且全面的证明了 KLL 算法能解决 All Quantiles Approximation Problem。
根据以往经验可知:
- 多层级的树状模型能满足空间要求并且解决 All Quantiles Approximation Problem(MRL 算法)。
- 对数据流的随机抽样策略解耦了误差与数据量大小的关系,但是单独使用空间效率不如 MRL 算法高(Sample 算法)。
- 相对距离表示的数据结构 + 不同层级不同 Sketch 大小的策略提高了空间利用率(GK 算法)。
- 融合多层级树状压缩模型 + 随机抽样的策略能够产生 unbiased Estimator 并且带来更高效的空间利用率(ACHPWY 算法)。
KLL 算法则把这四点融合起来,并加以改进,形成了这个更优的算法。
下图展示了 KLL 算法融合迭代的过程:
- 第一层为使用空间指数级增大的 Sketch 结构的算法。
- 第二层将部分低层级的 Sketch 替换为 Sampler 的结构。
- 第三层将顶层 Sketch 结构替换为等大小的 Sketch 结构并使用 MRL 算法的思想。
- 第四层再次将顶层 Sketch 结构替换成等大小的 Sketch 结构并使用 GK 算法的思想。
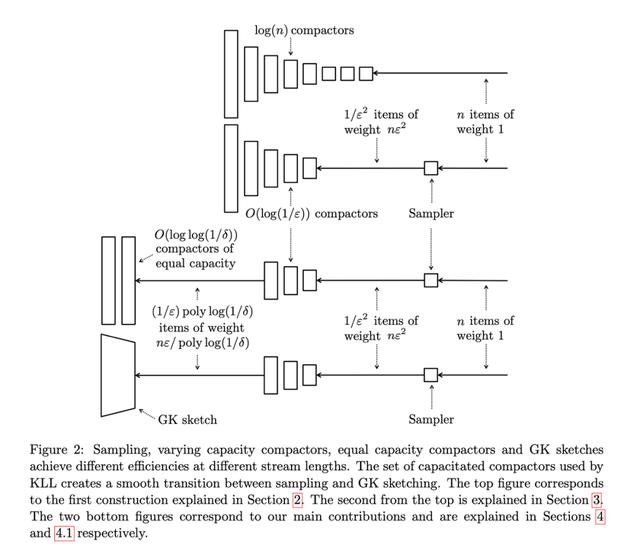
Sketch 空间指数增加设计
首先,为了节约空间,KLL 算法在 ACHPWY 算法基础上将多层级同样大小的压缩结构转化为指数级增大的压缩结构。原理很好理解,数据刚输入的时候没有经过过多的压缩,没有带来更多的误差,自然需要更大的空间去限制误差的增大。但随着数据不断压缩合并,丢失的信息越来越多,自然需要更大的空间去限制误差增大的趋势。

Bernoulli Sampler
随着层级的降低,低层级的 Sketch 结构空间大小不断减小逐渐趋近于最小空间 2。如果空间小于 2,那么 Sketch 结构没有办法进行正常的压缩。如果空间等于 1,Sketch 结构将变成一个没有意义的数据传输通道。那为何不把这些等于 2 的 Sketch 结构换成一个简单的 Bernoulli Sampler 呢?这样能够在解耦合数据量大小的时候还将 Quantile Estimator 转化成一个 unbiased Estimator,还能更进一步节省空间。空间大小将不再与数据量大小有任何关系(即是这个空间大小大约之前提到的算法的最优解)。这种方法的所需空间大小为:
要想理解为什么这个结构能够将所需空间和数据大小独立开来,需要想象这么一个过程。随着新的数据不断的流入,在原本的最高层级 H 被装满后,自然会压缩合并出下一个更高层级 H+1。那么假设 H+1-> H,我们知道,为了保证误差的收敛,对于 Sketch 大小是根据下面这个公式算出来的。不难发现,当新的一个层级取代旧层级后,每一层级的 Capacity 其实都缩小了 1/c 倍。直到这个层级大小小于 2 的时候,Sketch 结构便转化成一个 Bernoulli Sampler。将过小的 Sketch 结构 吸收到 Sampler 结构里使得整体的空间大小保持不变,是这个结构的核心优势。
上层空间的进一步优化
在此基础上,KLL 另一个核心发现是,大量的误差主要由最上面的几层 Sketch 结构导致。优化最上面几层的结构将大大降低误差。KLL 算法提出将最上层的 s 个 Sketch 从指数大小关系转化成固定大小关系(新的 Sketch 的空间大小不一定等于最高一层 Sketch 的空间大小),换句话说,将最上层的 s 个 Sketch 用 MRL 算法来实现。这种方法的所需空间大小为:
追求极致
为了追求极致的空间要求。KLL 算法提出用 GK 算法取代用 MRL 算法来实现最上层的 s 个 Sketch,因为理论上 GK 算法的所需空间更加的小。KLL 算法提出,将上层 s 个 MRL Sketch 拆分成两个紧密相连的 GK Sketch,使得在任何合并的时候,都会至少有一个 GK Sketch 有数,并给出证明这种大融合的结构能够达到的最优空间为:
但是不得不提及的是 KLL 算法作者们没有给出 Fully mergeable 的证明,也无法保证 Fully mergeable 的存在。因为 GK 算法只支持 One-way mergeable,本身就不是 Fully mergeable 的。所以业界实现的时候,通常选用上层为 MRL Sketch 的方法实现。
总结
到这里,这篇文章从 Sketch 结构的定义和特性出发,解释了 Sketch 结构如何解决大数据计算场景中海量数据计算痛点,明确了 Quantile 问题的定义。其次,结合大数据开发中常用组件,讨论了如何将 Quantile Sketch 算法带入工程实践中。本文着重介绍了 Quantile Sketches 算法原理,涵盖了算法发展的几个重要阶段和重要产物。笔者尝试用最简单的语言和逻辑讲解了每一个算法的核心思想、优点和缺陷,尝试将多种算法的发展串联起来,方便没有相关背景的人从零开始了解这个领域。但实际上 Quantile Sketches 算法仍然有很多的变种,例如为解决长尾分布而优化的 Quantile Sketches 算法,为计算精确 PCT 边界值而设计的 Digest 类算法[22][23],根据 Histogram 估计分位数的 Sketches 算法等……
希望大数据开发同学能够了解算法推论、证明、衍生,期待有朝一日能看到以你们名字命名的 Quantile Sketches 算法。
加入我们
抖音基础体验数据团队为体验相关策略、算法、工程、客户端提供数据支持,抖音日活过 6 亿,我们在流式和离线数据处理、数据仓库、实时OLAP等方面积累了丰富经验,但也仍面临更复杂场景、更大数据量等业务和技术的挑战,欢迎一起解决业界top级的难题。
另外,我们所属抖音基础体验部门有架构、工程、算法、数据分析和产品经理等职位,我们 base 包括北京、上海、深圳和山景城,欢迎通过下方链接加入我们!
- 大数据研发工程师 https://job.toutiao.com/s/YFkppvf (北京) https://job.toutiao.com/s/YFS8uob (深圳)
- 更多相关岗位请联系 limingyue.tammy@bytedance.com
参考文献
1.https://datasketches.apache.org/
2.https://datasketches.apache.org/docs/Quantiles/Definitions.html
3.https://datasketches.apache.org/docs/Architecture/SketchFeaturesMatrix.html
4.https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/ApproximatePercentile.scala#L80
5.https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/QuantileSummaries.scala
6.https://github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDAFPercentileApprox.java
7.https://www.jmlr.org/papers/volume11/ben-haim10a/ben-haim10a.pdf
8.https://github.com/apache/datasketches-java/blob/master/src/main/java/org/apache/datasketches/quantiles/DoublesSketch.java
9.https://www.cs.utah.edu/~jeffp/papers/merge-summ.pdf
10.https://link.springer.com/chapter/10.1007/978-3-642-14553-7_11
11.https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.86.5750&rep=rep1&type=pdf
12.https://epubs.siam.org/doi/pdf/10.1137/1.9781611972740.53
13.http://courses.csail.mit.edu/6.854/20/sample-projects/B/streaming-quantiles.pdf
14.https://zhuanlan.zhihu.com/p/45342697
15.http://infolab.stanford.edu/~datar/courses/cs361a/papers/quantiles.pdf
16.https://blog.csdn.net/matrix_zzl/article/details/78641264
17.https://blog.csdn.net/matrix_zzl/article/details/78660821
18.http://www.mathcs.emory.edu/~cheung/Courses/584/Syllabus/08-Quantile/Greenwald.html
19.http://www.mathcs.emory.edu/~cheung/Courses/584/Syllabus/08-Quantile/Greenwald2.html
20.http://www.mathcs.emory.edu/~cheung/Courses/584/Syllabus/08-Quantile/Greenwald-D.html
21.https://arxiv.org/pdf/1603.05346.pdf
22.https://bbs.huaweicloud.com/blogs/259254
23.https://dataorigami.net/blogs/napkin-folding/19055451-percentile-and-quantile-estimation-of-big-data-the-t-digest
如若转载,请注明出处:https://www.jiangsasa.com/7513.html
相关推荐
-
康熙字典取名大全免费_康熙字典取名大全免费查询
在中国传统文化中,取名是一项非常重要且讲究的艺术。名字不仅是一个人的符号,更承载着父母对孩子的美好期望和祝福。随着历史的发展,取名的方式与理念也经历了诸多的变化,其中“康熙字典”作…
-
购的拼音_烧的拼音
在当前的时代,网购已经成为了人们日常生活中不可或缺的一部分。随着互联网的快速发展,网购逐渐成为了人们购买商品的首选方式,无论是日常用品、服装鞋帽还是食品等各种商品,我们都可以通过网…
-
马的名字大全男孩(古代马的名字大全)
我们常吃的“士力架”其实是一匹马的名字?篮球巨星科比 布莱恩特的名字来自于一种牛排?白雪公主的7个小矮人不仅有名字而且还充满着深意?原来还有这么多我们不知道的有趣冷知识,还等什么,…
-
安字取名男孩名字大全_安字取名男孩名字大全三个字
在中华文化中,名字不仅是一个人的象征,更寄托着父母对孩子的期望与祝福。取名作为一门艺术,显得尤为重要,尤其是对于男孩更是如此。今天,我们将针对“安”字进行深入探讨,提供一份独特的三…
-
何宝文百度?何宝文个人资料简介!
一路走过来,这路真是难走。坎坷,荊棘,山山,水水,亲亲,我我,弯弯曲曲,爬山跋水。原本就没有路,走的人多了边就成了路。 走到今天总算弄明白了什么叫路,从呱呱坠地,到邯郸学步。摔倒了…
-
三人闺蜜群名沙雕搞笑?三人闺蜜群名沙雕搞笑英文!
我下了班,我就跟他一起吃个饭,吃饭的过程中他一直在说他最近的情况,工作等等。他说的时候我偶尔应了一声哦哦。然后他给我说祖欣冉找他了,祖欣冉就是他的那个女同学。我问了他祖欣冉不是跟王…
-
起名字大全男孩姓李嘉姓李嘉的男孩名字有哪些!
本排名仅代表个人看法,有不同的看法可以留言评论。 唐太宗李世民 李世民,大唐第二位皇帝,雄才伟略、英明神武,是一位有作为的政治家和军事家,在反隋建唐的斗争中起着领导作用。唐太宗励精…
-
解姓起名男孩起名_解姓起名男孩起名大全
作为家庭中的新成员,给孩子起名是每个家长的重要任务之一。许多家长会精心挑选名字,以确保孩子有一个独特而且有意义的名字。其中,解姓是一个较为常见的姓氏,选择适合男孩的解姓起名需要考虑…
-
彭姓取名字大全男孩2024_彭姓取名字大全男孩2024年
在2024年,许多父母都在寻找符合时代潮流并且有深意的姓名为自己的婴儿取名。如果您的姓氏是彭,那么您可能迫切希望能找到一些适合男孩的名字。取名并不仅仅是为了满足文化传统或者个人爱好…
-
周易取名网唯一官方免费取名周易取名网免费取名!
一个人,无论是富有还是贫穷,老了的时候都会像蜡烛一样燃烧而死,毕竟生老病死是人之常态,谁也无法避免,但只要能够好好活着,谁又会想不开作死呢? 可是人一旦开始变老,各种问题就开始出现…